Xpath语法
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的计算机语言。
XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型。但是XPath很快的被开发者采用来当作小型查询语言。
语法
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
Python
python使用lxml进行解析
from lxml import etree
html=etree.parse('d:/github.html',etree.HTMLParser(encoding="utf-8"))
result = html.xpath('''//*[@id="org-repositories"]/div[1]/div/ul/li[1]/div[1]/div[1]/h3/a/@href''')
for row in result:
print(row)scrapy框架也支持xpath解析
proxy = {
'http': 'http://dev:7890',
'https': 'http://dev:7890'
}
resp = requests.get(base_url,verify=False,proxies=proxy)
# %%
print(resp.text)
# %%
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
response = Selector(text=resp.text)
for elem in response.xpath('//*[@id="main"]/article'):
title = elem.xpath('string(./header/h1/a)').extract_first()
url = elem.xpath('./header/h1/a/@href').extract_first()
next = response.xpath('//a[@rel="next"]/@href').extract_first()
Java
Java可以使用htmlcleaner解析HTML
<dependency>
<groupId>net.sourceforge.htmlcleaner</groupId>
<artifactId>htmlcleaner</artifactId>
<version>2.6.1</version>
</dependency>我这里代码使用Groovy写的,和Java写法有点差异
HtmlCleaner hc = new HtmlCleaner()
def node = hc.clean(new File("d:/github.html"))
println node.getElementsByName("title",true)
println node.evaluateXPath("//*[@id=\"org-repositories\"]/div[1]/div/ul/li[*]/div[1]/div[1]/h3/a/@href")获取xpath
我们可以通过Chrome的开发这工具来获取xpath,但这种方式获取的xpath不是很友好,只是单纯的将所有的路径都显示出来。

可以安装
EasySelect这个Chrome扩展,可以很方便取到我们想要的数据。
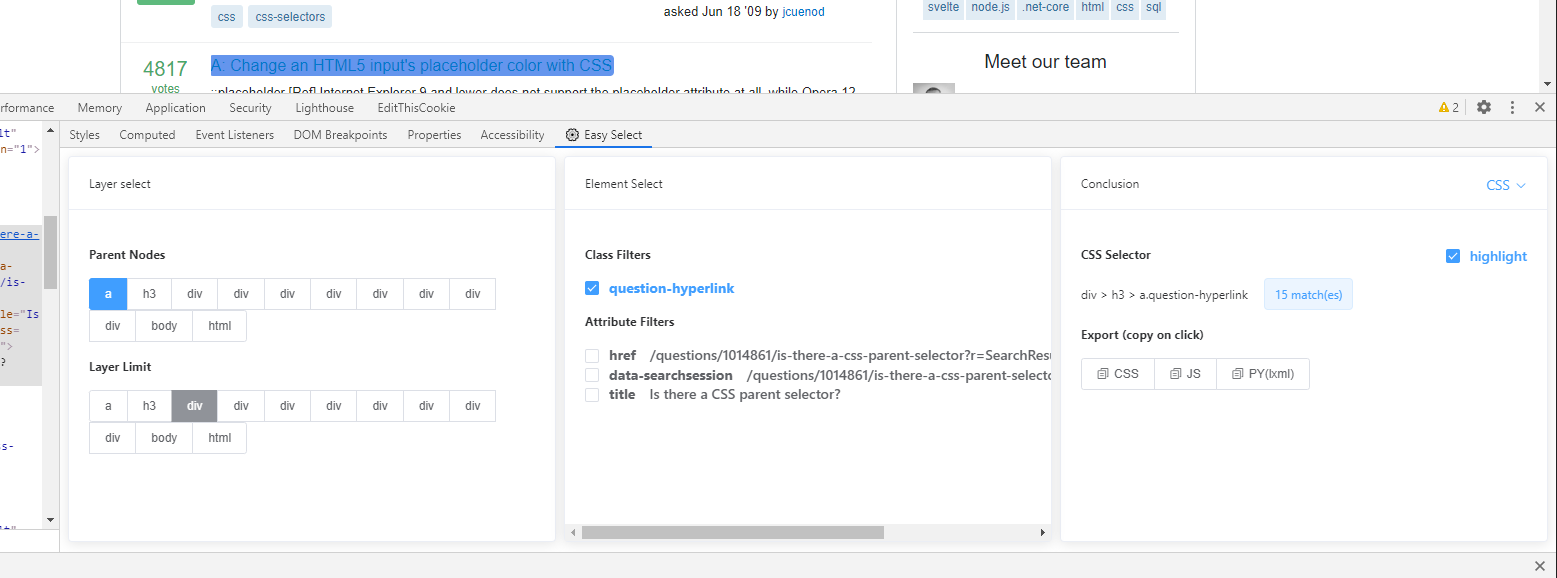
工具
再安利一个小工具,可根据curl命令生成代码。
Convert curl syntax to Python
Xpath语法
https://blog.yjll.blog/post/d16b66c8.html